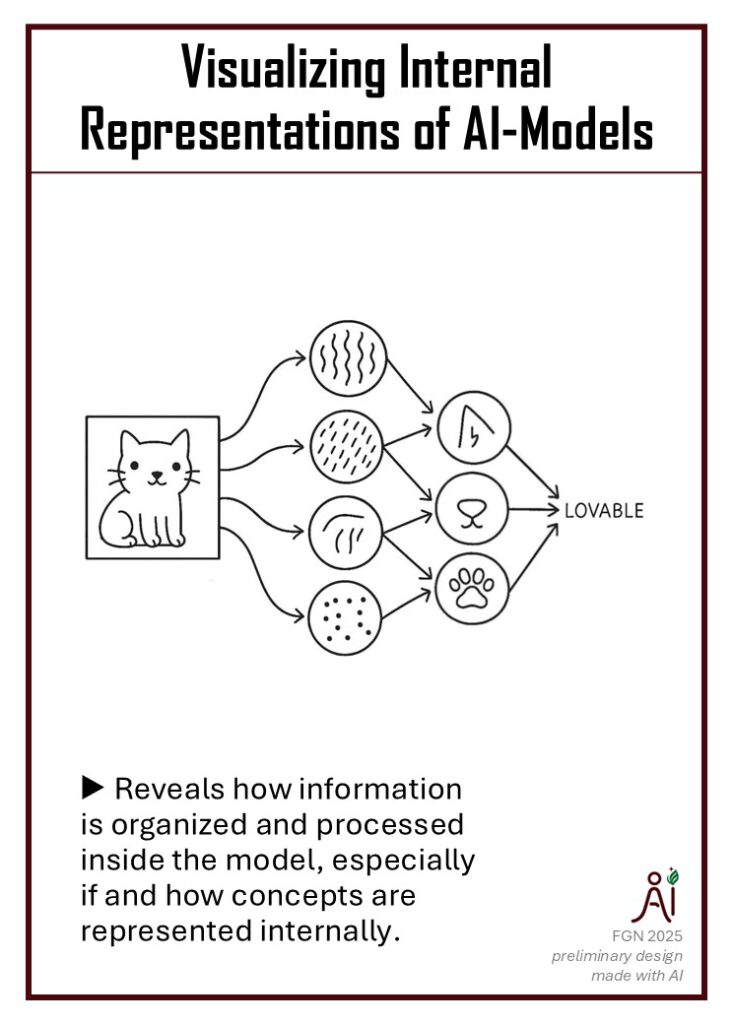
Visualizing internal representations of models, such as deep neural networks, helps to make them more transparent. Visualizations can reveal hierarchical feature extraction processes and demonstrate decision pathways. Developers can utilize these to gain a deeper understanding of how models process inputs and arrive at decisions. This transparency not only facilitates debugging and model improvement, but it can also enhance user trust by showing that the model is reasoning in expected ways rather than relying on spurious correlations.
Example Methods
- Attention visualization: Displaying attention weights in transformers or other models to highlight influential input components.
- Chain of Thought reasoning: Breaking decisions into interpretable logical steps within model architecture.
- Circuit discovery: Identifying subnetworks or data flow responsible for specific behaviors.
- Probing methods: Testing what linguistic or semantic information internal layers capture.
- Methods for dimension-reduction of high-dimensional internal feature spaces/ learned representations
- t-SNE, UMAP, etc.