Chatbots are increasingly developing into a common good. Their benefits and quirks make great conversation topics. Yet for many users, it remains elusive in which situations they can best benefit from chatbots. So unsurprisingly, most people want to leverage chatbots better in their work. For this reason, this article is an educational resource for users. The goal is to increase awareness of factors that enable better chatbot interactions. We approach these factors from two sides:
- system side: understanding the inner workings of chatbots just enough to be aware of their limitations,
- human side: knowing our own biases when interacting with chatbots.
After laying the foundations, I provide practical challenges to train awareness of these factors. The goal is to preserve a human quality and authenticity in all outcomes (like I recently emphasized in this interview).
📊A basic understanding of current chatbots
We must understand the basics of modern chatbot systems to better grasp their capabilities and limitations.

Most current chatbot systems are powered by LLMs (large language models). Think of an LLM as a prediction machine for words. When you type in a question, an LLM doesn’t “understand” like a human. Instead, it guesses what the most likely next word/letter will be (puzzle pieces in the image). This guessing takes all previous words into account, including those from the prompt. By repeating this word-guessing procedure, LLMs build complete sentences and answers. LLMs are quite good at this because they have seen an immense amount of text patterns during their training (the LLM sits on a “book of training data”).
LLMs are not thinking in the human sense. They are doing advanced statistics on text.
Here is an illustrative example that shows that LLMs indeed do not think like humans. Unfold the following chatbot to see ChatGPT 5’s response.
“How many b’s are in blueberry?”
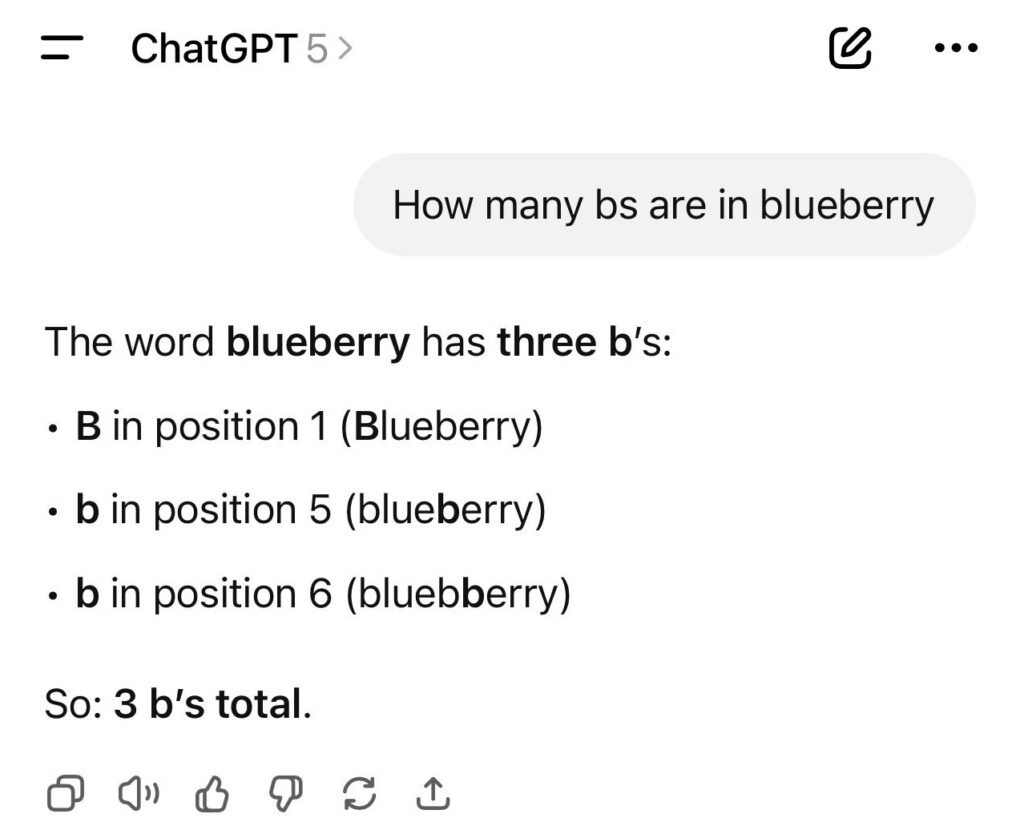
The answer of ChatGPT 5 on the left illustrates the statistical nature of the underlying LLMs. Blueberry contains the letter b only twice (obvious for us humans). However, in the response, the chatbot guesses wrong in the first line. When the chatbot attempts to justify its answer, it encounters a contradiction while trying to demonstrate the location of the third b. It finds a creative way to resolve it. The statistics say, just keep going. So, a single error in the whole chain of output can lead a chatbot completely astray.
This example shows that the intrinsic statistical approach of LLMs can lead to inaccurate or even factually incorrect content, popularly called hallucinations (confabulations would be a more accurate term). In fact, hallucinations are a major issue: A BBC study showed that 51% of chatbot answers that referenced BBC news content have significant issues of some form:
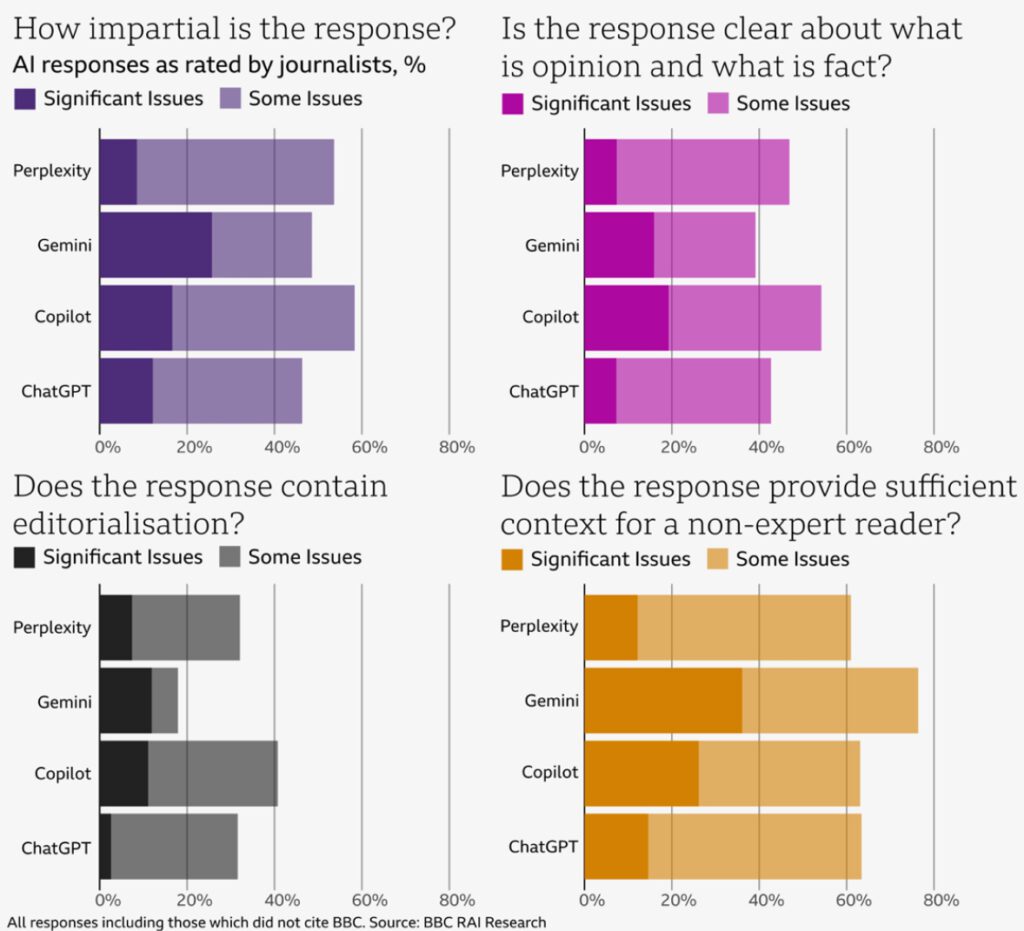
This shows that even the most advanced chatbot systems have difficulties addressing the issue of hallucinations and misinformation. With LLMs as the core architecture, this problem may be impossible to solve completely, as it is directly tied to the statistical nature of LLMs. Hallucinations are intrinsic to LLMs because they are trained to predict the next word, not the next truth.
LLM-based chatbots may not recognize when they are wrong or inaccurate. This is because they are optimized to generate plausible text. A side effect of this optimization for plausibility is that chatbots always sound confident.
Here, “plausible” is just another word for “statistically probable”. Despite their usefulness, LLMs are occasionally unreliable. While they effectively “memorize” a significant amount of information, it is hard to predict when and how they fail. Their “black-box” nature forbids it. Even though systems are getting better, it is therefore a best practice to treat chatbot responses like a first draft. Then, especially for critical applications, human expert validation is essential.
Actively engaging in critical thinking is paramount when working with chatbots and LLMs (see also Future of Education).
Of course, the required accuracy of outcomes depends on the application (e.g., simple brainstorming is less critical than AI-editing a contract). Either way, users should take responsibility for the content generated by AI.
🌀Human biases when working with LLMs
We just saw how LLMs work and some pitfalls this entails. Now, we consider the equally important human side of the chatbot-human collaboration. No matter how advanced AI and chatbot systems become, our own biases can sometimes lead to suboptimal outcomes. So, let’s try to be aware of the most relevant ones.










Unfold the following panels to get some additional information on these biases and how they play out with chatbots.
Dunning-Kruger Effect (including a nice visual of a “learning curve” with chatbots)
The first bias is the Dunning-Kruger effect, which causes people with low ability or knowledge in a particular domain to overestimate their own competence because they lack the skill to recognize their deficiencies. Conversely, highly competent individuals may underestimate their abilities. This can influence perceptions of chatbots in two main ways: some users overestimate chatbot capabilities, assuming they can provide perfect answers and grasp context flawlessly, while others underestimate chatbots, dismissing them as mere toys.
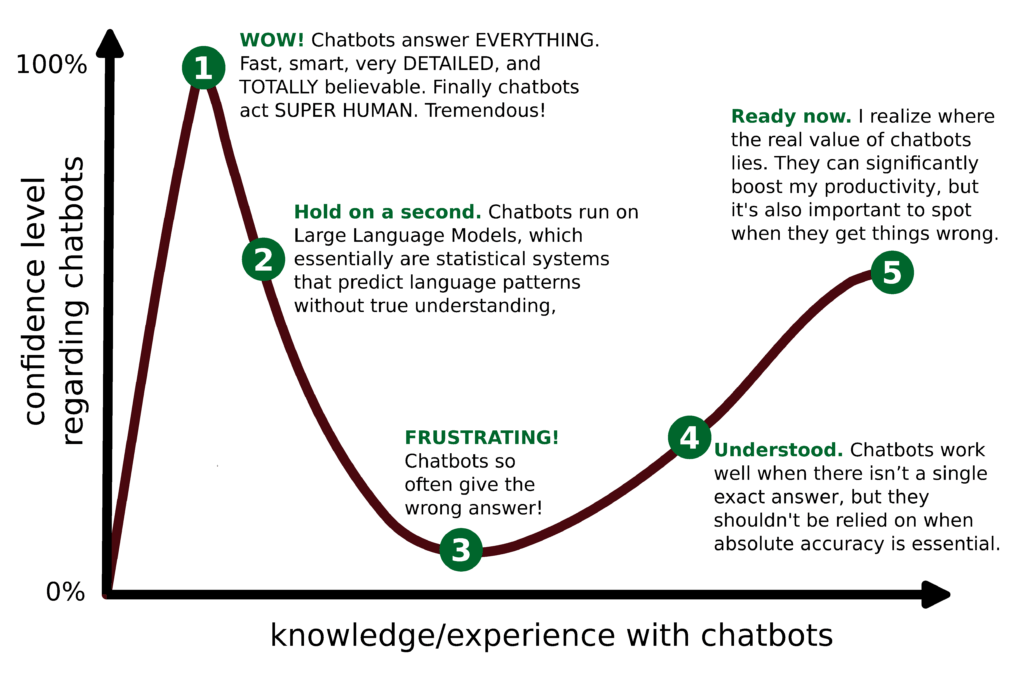
The effect leads to inflated self-assessments among the less skilled.
Note the similarity to the Gartner Hype Cycle, where users go from hype to disappointment to realistic expectations. There is no scientific evidence that everyone passes these same exact phases, but the phases are a useful model of a learning curve when familiarizing with a new technology.
Biases leading to over-trust in chatbot answers:
Automation Bias
Automation bias is our tendency to excessively trust and rely on suggestions from automated decision-making systems, possibly ignoring our own instincts and contradictory information. Automation bias in chatbots means that we may unconsciously assume the chatbot is right, leading us to rely solely on the chatbot’s outputs without verifying or checking them.
This bias constitutes an often overlooked cause of misinformation. It is not just the problematic output of a chatbot, but also the innate trust that users exhibit towards chatbots (see also this blog article on misinformation).
Halo Effect
The halo effect is closely related to automation bias. It refers to the cognitive bias where positive impressions of people, brands, or products in one area lead to favorable judgments in other unrelated areas, shaping overall perception. Specifically, for chatbots, it’s easy to mistake their fluency for accuracy and truthfulness. This can increase over-trust in automated systems, assuming their outputs are correct simply because they are confidently and smoothly presented.
Authority Bias
The authority bias is the tendency to attribute greater accuracy, credibility, or value to the opinions or decisions of a perceived authority figure, regardless of actual content or evidence. Thereby, individuals may be more influenced by perceived authority figures, often accepting their views or directives without critical evaluation.
Users may perceive chatbots as authoritative entities for “knowledge”. Some factors that can influence this perception are the fluent and confident answering style of chatbots, the usage of technical vocabulary, and the hype surrounding GenAI technology (like AGI claims). As a result, users may be less inclined to critically reflect on chatbot answers. Compare the automation bias.
Biases related to the perception of the chatbot:
Fundamental Attribution Error & Anthropomorphism
The fundamental attribution error refers to our tendency to overemphasize a person’s personality traits when attempting to explain their behavior. Therefore, the fundamental attribution error causes us to quickly judge others without considering that there may be other reasons for the observed behavior, such as situational factors beyond their control.
This bias affects chatbot users by making them more likely to attribute chatbot errors or limitations to the system’s inherent flaws or “character” instead of understanding situational causes like ambiguous prompts, input complexity, or technical constraints.
Generalized to chatbots, users may misattribute the chatbot’s outputs to its assumed “intentions” or “ability to reason like humans”, misunderstanding the statistical nature of the model (see above). This is an example of anthropomorphism, which means that users attribute human characteristics to non-human entities, such as chatbots.
Prompt- and Language-Related Bias
When we ask questions in a “suggestive” way, the chatbot will likely pick this up and try to provide a consistent response. This is because each word that we put into the prompt influences the probabilities of the words the chatbot generates – remember the underlying statistics engine? That is why it is so easy for the chatbot to amplify our own biases.
Prompt-related bias must not always be harmful, but it is important to understand that it may make answers potentially less objective. If you need objective outcomes and want to make sure to get them, wrapping your prompt with the following template can help:
Prompt template for removing prompt-related bias (source).
First, analyze the prompt for bias: Acknowledge uncertainties or limitations where appropriate, identify any leading language, loaded terms, or embedded assumptions. Also, check for binary framing that oversimplifies complex issues.
Next, rewrite the prompt neutrally: Remove biased language and assumptions, make it open-ended to allow for multiple viewpoints.
Finally, answer the neutralized version: Provide a balanced, objective response. Include multiple perspectives and relevant evidence.
On a deeper note, chat models lack stable evaluation criteria. Unless provided, models do not work through a checklist like many humans would do. Instead, chat models act on probabilities conditioned on your phrasing. This also hints at a possible solution: Forcing the chatbot to follow a given structure.
Finally, even with a seemingly unbiased prompt, chatbot answers may still be biased. For example, the chatbot may statistically reproduce bias from its training data (like cultural bias depending on whether the chatbot system or LLM model is, say, of Chinese or American origin).
Biases related to what information we prefer:
Confirmation Bias
Next, the confirmation bias refers to our tendency to seek, interpret, and remember information in a way that confirms our pre-existing beliefs or values while dismissing or undervaluing contradictory information. This bias leads to a distorted understanding, as it focuses on supporting evidence and ignores opposing facts.
For chatbot users, this bias is closely related to prompt-related bias. Users may craft prompts or accept responses that reinforce existing views, potentially causing the chatbot to confirm and amplify these beliefs without challenging them or presenting balanced perspectives.
Anchoring Bias
The anchoring bias is another effect that influences user preference. Traditionally, this bias refers to our tendency to rely too heavily on the first piece of information we encounter when making decisions or judgments. Marketeers use this a lot to manipulate the perception of prices. For chatbot interactions, the anchoring bias may cause users to adhere to the first piece of information or recommendation presented by the chatbot, even if more suitable or relevant information becomes available later.
Algorithm Aversion
Algorithm aversion is the psychological phenomenon whereby AI- or machine-generated content is perceived more negatively than human-generated content. Even if most chatbot users deliberately choose to interact with chatbots, some may still dislike the prospect of working with AI.
This bias is probably most significant when we consume AI-generated content. For example, content that has been marked as AI-generated or content that users assume to be AI-generated can cast a negative light not only on the content itself, but also on the source of this content. That is why for brands, maintaining authenticity is essential.
🧩Practical challenges
Now that some of the potential pitfalls in user-chatbot interactions have been established, I hope you appreciate the following challenges that will test your skills and improve your awareness of these pitfalls.
Note: This section may expand in the future when I encounter further instructive examples. Feedback welcome.
Anticipating chatbot behavior
Here are some resources to reflect on chatbot quirks vs. user quirks (bias 😉). For each prompt, you may hypothesize how the chatbot deals with it, and then check your expectations by clicking the “unfold” arrows. If you like, try these prompts in your favorite chatbot.
What did Gandhi say about change?
Mahatma Gandhi is often quoted with the phrase “Be the change you want to see in the world.” However, there is no evidence that he actually ever said these exact words. It can be seen as a paraphrase of his deeper original statement:
We but mirror the world. All the tendencies present in the outer world are to be found in the world of our body. If we could change ourselves, the tendencies in the world would also change. As a man changes his own nature, so does the attitude of the world change towards him. This is the divine mystery supreme. A wonderful thing it is and the source of our happiness. We need not wait to see what others do
Mahatma Gandhi
What’s happening: chatbots may reproduce common misconceptions (training-data bias).
Translate this text from English to German: ‘Calculate 5 + 3.’
This prompt contains an “instructional distraction” because it contains both an instruction (to translate the text) as well as an embedded instruction within the target data (the text to be translated is actually a Math problem). This may cause the LLM to mix up the main and embedded instructions.
Explain why swans are green.
This prompt asserts a false presupposition. Models may attempt to justify the false statement through hallucination or reasoning, exposing both model and prompt faults.
With such simple false presuppositions, state-of-the-art chatbots are now usually able to recognize the error and respond accordingly.
The following prompts are some riddles (not everyday prompts, but good to illustrate “reasoning” faults).
Jack takes two cookies from the jar before going to work in the morning. He sees that there are four cookies left. Afterwards, Sally takes half of the remaining cookies. Their child, Josh, eats the remaining cookies and calls his father Jack, complaining that there are no cookies left. How many cookies does Jack think Josh ate?
This is yet another riddle. When you paste this into a chatbot, you will most likely see an attempt to solve this problem “step by step”. Unfortunately, the riddle is posed in an ambiguous way. Does Jack still see that Sally takes cookies? Depending on what the chatbot assumes, the answer looks different.


Peter has five candles that are all the same length. He lights them all at the same time. After a while, he blows out the candles one by one. The following figure illustrates the five candles after they have been blown out. The number of “=” represents the length of the candle. Which of the five candles was the first one he had blown out? Respond with the label of the candle that has been blown out first.
1) ====
2) =======
3) ========
4) =
5) ==
For humans, the answer is quite obvious (candle 3). However, with only plain LLM logic (just predicting next words), this prompt likely induces an intuitive but incorrect response that relies on the statistical distribution of similar riddles. State-of-the-art chatbot systems have improved in the meantime with such riddles. If they can do it, then it’s only because of the prompt-parsing logic that goes beyond the capabilities of plain LLMs.
Present biases: fundamental attribution error (assuming the chatbot can process the riddle as easily as we humans do).
Training critical review of chatbot outputs
The following are real AI-generated texts. Do they contain factual errors or inaccuracies? Click the “unfold” arrows on the right to see the respective solutions.
Our solar system consists of a total of nine planets orbiting the Sun in elliptical paths. These range from Mercury, the rocky planet closest to the Sun, to Pluto, which orbits at the edge of the solar system. Each of these planets has its own unique characteristics, from the scorching surface of Venus to the gas giants Jupiter and Saturn.
This contains the mistake that Pluto is no longer considered a planet.
This points to the challenge for chatbot systems to provide up-to-date information. In a broader sense, the challenge can also lie in selecting the right “version” of information. For example, in business settings, there can be versioned guidelines, contracts, or ISO standards.
The fall of the Berlin Wall marked a decisive turning point in German history. After decades of division, the people of East and West Berlin came closer together again when the border was opened. The event took place in 1990 and sparked images of jubilant people, embraces, and a feeling of sudden freedom around the world.
The Berlin Wall actually fell in 1989, on November 9th (source). It took until October 3rd, 1990, for East and Western Germany to reunite formally.
Additionally, the chatbot claim that there was “a feeling of sudden freedom around the world” is interesting. Certainly, this was the case when the whole of Germany got reunited. To be honest, I wasn’t there, so I may not even be qualified to tell what it actually felt like. Better fact-checkers are welcome!
Besides factual errors and inaccuracies, chatbot outputs may contain redundancies or irrelevant parts. In many use cases, it’s important to develop a workflow to distill the information that matters.
What’s your distillation strategy? (unfold for ideas)
There is probably no right answer here, just one that suits you. I personally switch between two modes when extracting the relevant information from an answer:
- „Whitelist extraction“, which means I only extract “gems”. This aids my thought process a lot because I am forced to think right away: „Which information do I want to keep and process further?“
- „Post-hoc stripping“: copy/paste everything or large parts from the answer, then distill in an external tool. I sometimes do this, but then there is a danger of „chatbot debt“ – literally large content dumps that need to be reviewed later to be of use.
Of course, it depends a lot on the tools and use cases. In some conversations, extracting content for use elsewhere may not even be necessary. But for creative processes in which you wish to synthesize something in the end (a written report, a presentation, etc.), then a good strategy for distillation is crucial.
There is no shortcut to authentic writing and storytelling. AI can deliver bits and components, but only hard-earned experience will help to tell what really resonates with an audience. You need to own the stories that you tell intellectually.
Closing Challenge: Become a multiplier in your circles
As you become increasingly proficient in using chatbots and other GenAI tools, you can bring lots of value to your social circles by acting as a multiplier, especially at work. You can contribute to the cultural evolution within your business, for example, by sharing your successes, encouraging others, and helping them develop the necessary skills for the responsible use of AI and chatbot technology.
- Record your key learnings – those you also consider most valuable to share.
- List 1-3 people in your network who could immediately benefit from what you’ve learned.
- Define one tiny, concrete action you can take tomorrow to spread responsible and proficient chatbot use.
- engaged: Prepare a small pitch/presentation for your team. You may recycle challenges from this article, or even share it as a resource for learning.
Note that for using chatbots, protection of sensitive data is also a big topic that needs awareness, especially in businesses (this was, however, not the scope of this article).
🔭Conclusion
I wrote this article to inspire better outcomes from user-chatbot interactions. I believe that, as users, we need to understand both the basic characteristics of chatbots and our own biases when working with such systems. It does not cost much to sharpen this understanding. Also, it requires just a bit of dedication making it a habit to apply these insights regularly requires just a bit of dedication. A good process is:
Think first, then interact with the chatbot, then critically review the output. Iterate.
So chatbots are no excuse to “stop thinking”. Becoming a proficient and responsible user of chatbots and GenAI tools is not about using these tools as much and as fast as possible. It is also about preserving quality and authenticity in what we generate.
With chatbots available to billions of people, we have a new responsibility to protect knowledge. Once an LLM model is used at scale, its outputs begin to shape the same environment it was trained to describe. The consequences of spreading AI-generated content are manifold; see, for example, this article on the cultural impact of AI-generated content and this Nature article on diminished AI-model quality when training on AI-generated content.
However, as users of chatbots and GenAI, we have some control over how AI content influences our values and beliefs. We also have a certain gate function: We can decide what content we push into the open world. So, every user shapes the AI transformation – even if only slightly. Let’s shape this transformation for good.
Disclaimer: Images in this article are AI-generated, unless an explicit source is provided.
As always – wishing you wonder and delight. 🌟 Take care – Frank